Human-level Atari 200x faster (Deepmind, 2022)
Deepmind的Agent57是第一个在57款Atari游戏上全面超过人类水平的强化学习智能体。但是Agent57的数据利用效率很低,要求80亿帧数据。本文通过设置不同的策略集合实现了200倍的训练效率提高。
4个关键点:
使用在线网络的近似信赖域的方法,实现稳定的Bootstrapping;
一个损失和优先级的正则化方案,可在学习具有大范围尺度的价值函数时,提高鲁棒性;
使用改进的NFNets的架构,不必normalization layers也可使用深层网络;
使用策略蒸馏方法,消除瞬时贪婪策略随时间的变化;
1 Introduction
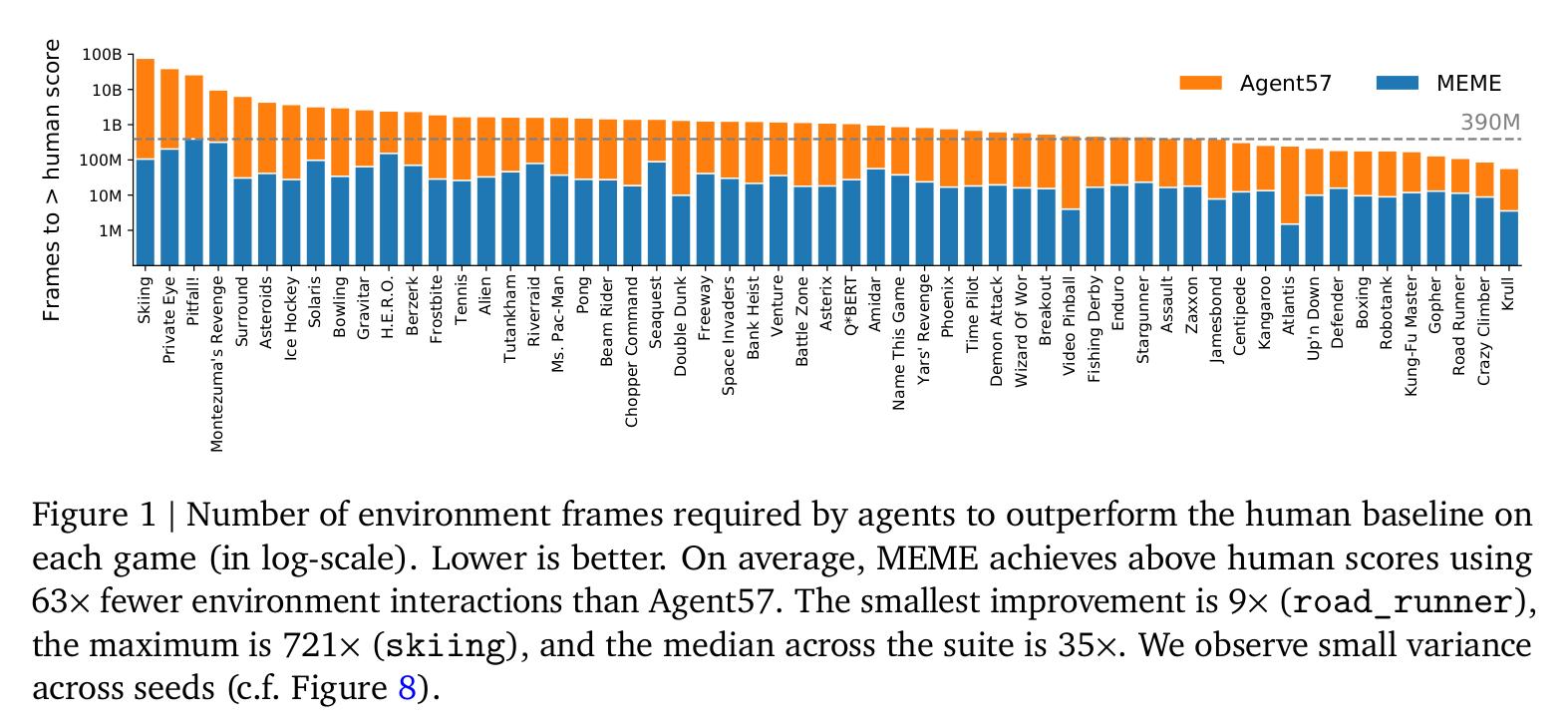
衡量agent学习能力的两种方式:
在与环境交互有限次后对比性能高低;
但该方法忽略了那些在允许的预算内难以解决的问题;
对比达到目标性能所需的交互次数;
本文为了和agent57对比,并凸显效率,采用该方式对比;
MEME (Efficient Memory-based Exploration agent):
针对所有策略的转换,并行训练Agent57的整个策略系列的价值函数,而不是仅是行为策略的转换?;
bootstrapping from the online network;
using high replay ratios